

稳定性是制约人形机器人落地的重要因素之一,如何利用强化学习,RL,与基于模型的控制,MBC,来进一步提高机器人的稳定性,已成当下业界的重要研究方向,2024年12月8日,、AI科技评论GAIRLive品牌联合石麻笔记一起举办了一场主题为,RL,Control,将机器人可靠性逼近99.9x%,的线上圆桌沙龙,圆桌主持人为石麻笔记主...。
更新时间:2025-02-01 14:27:31

在具有挑战性的环境中,一些人工智能系统通过利用过去经验所提供的世界表象来实现目标,研究人员将这些应用推广到新的情况,使它们能够在以前从未遇到过的环境中完成任务,事实证明,强化学习——一种使用奖励来推动软件策略朝着目标前进的训练技术——特别适合学习一个总结agent经验的世界模型,并通过扩展来促进新行为的学习,雷锋网消息,近日,来自Go...。
更新时间:2024-12-10 01:35:08

语音播放文章内容由深声科技提供技术支持您的浏览器不支持audio元素,雷锋网AI科技评论按,在过去的两三年中,我们经常听说人工智能在棋牌类游戏,博弈,中取得新的成果,比如基于深度强化学习的AlphaGo击败了人类世界冠军,由AlphaGo进化而来的AlphaZero还一并搞定了国际象棋和日本象棋;基于博弈论的冷扑大师,Libratus...。
更新时间:2024-12-10 01:27:39

译者,AI研习社,季一帆、,在强化学习中,我们使用奖惩机制来训练agents,Agent做出正确的行为会得到奖励,做出错误的行为就会受到惩罚,这样的话,agent就会试着将自己的错误行为最少化,将自己的正确行为最多化,本文我们将会聚焦于强化学习在现实生活中的实际应用,很多论文都提到了深度强化学习在自动驾驶领域中的应用,在无人驾驶中,需...。
更新时间:2024-12-10 01:25:44

人工智能技术一旦完全投入使用,它有可能拯救这个世界,也有可能终结这个世界,近日,VentureBeat与,谷歌大脑,的联合创始人吴恩达、Facebook人工智能研究院创始人YannLeCun等业内专家进行了对话,并将他们的观点整理成文,雷锋网AI科技评论选取了吴恩达和YannLeCun的观点进行编译,一起看看他们认为2018年有哪...。
更新时间:2024-12-10 00:42:43

雷锋网AI科技评论按,2018年5月31日,6月1日,中国自动化学会在中国科学院自动化研究所成功举办第5期智能自动化学科前沿讲习班,主题为,深度与宽度强化学习,如何赋予机器自主学习的能力,一直是人工智能领域的研究热点,在越来越多的复杂现实场景任务中,需要利用深度学习、宽度学习来自动学习大规模输入数据的抽象表征,并以此表征为依据进行自...。
更新时间:2024-12-10 00:09:43

雷锋网AI科技评论按,日前,谷歌在Nature合作期刊,npjQuantumInformation,上发表了一篇论文,提出结合深度强化学习的方法来实现通用量子控制,从而能够极大地提高量子计算机的计算能力,谷歌也在官方博客上发表文章介绍了这项工作,实现近期量子计算机的主要挑战之一与其最基本的组成有关,量子比特,量子位可以与任何携带与自身...。
更新时间:2024-12-10 00:03:08

作为Facebook人工智能部门主管,YannLeCun是AI领域成绩斐然的大牛,也是行业内最有影响力的专家之一,近日,LeCun在卡内基梅隆大学机器人研究所进行了一场AI技术核心问题与发展前景的演讲,他在演讲中提到三点干货,演讲完整视频如下,该视频长75分钟,并包含大量专业术语,因此雷锋网节选关键内容做了视频摘要,以供读者浏览,以下...。
更新时间:2024-12-09 23:43:52

AI,物理,成功破圈,DeepMind怕是要上天,北京时间凌晨四点,DeepMind在官方推特上发布消息,称其与瑞士洛桑联邦理工学院,EPFL,合作研究出第一个可以在托卡马克,Tokamak,装置内保持核聚变等离子体稳定的深度强化学习系统,为推进核聚变研究开辟了新途径,消息一出,立刻引起围观,收获一千多点赞、数百转发,据该工作的其中...。
更新时间:2024-12-09 23:00:00
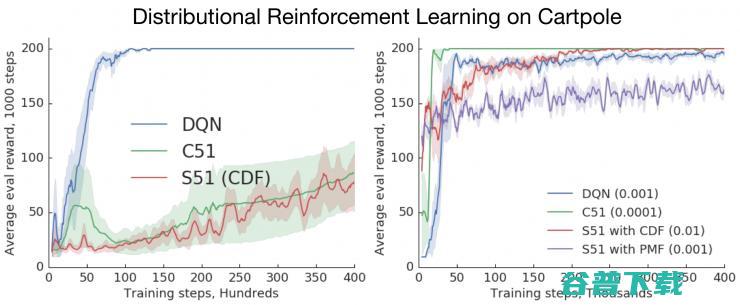
雷锋网AI科技评论按,在强化学习领域,谷歌大脑的研究内容一直是业界重点关注的对象,MarcG.Bellemare是谷歌大脑的研究员,研究方向为分布式强化学习、表征学习等,他将自己在谷歌大脑18个月中研究经历和心得写成了文章并进行发表,雷锋网AI科技评论全文编译如下,时间回溯到2017年夏天,在欧洲一段时间的告别旅行中,我被当时在蒙特利...。
更新时间:2024-12-09 22:02:11

腾讯正在联动高校,利用王者荣耀的复杂环境,为推动通用人工智能研究创造各种可能性,4月14日,第二届,腾讯开悟多智能体强化学习大赛,以下称,大赛,决赛在成都落幕,来自20多所顶尖高校的AI研发团队,经过半年来的比拼,共有4支团队进入决赛,经过现场激烈角逐,来自清华大学计算机系的团队获得本届大赛冠军,本届大赛由腾讯AILab、王者荣耀...。
更新时间:2024-12-09 20:53:13
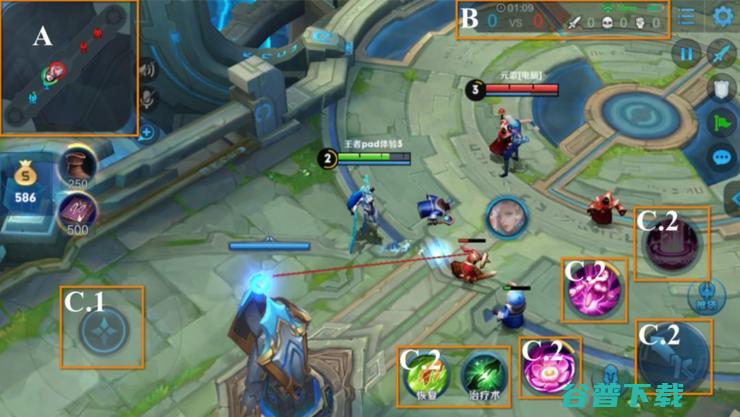
围棋被攻克之后,多人在线战术竞技游戏,MOBA,已经成为测试检验前沿人工智能的动作决策和预测能力的重要平台,基于腾讯天美工作室开发的热门MOBA类手游,王者荣耀,,腾讯AILab正努力探索强化学习技术在复杂环境中的应用潜力,本文即是其中的一项成果,研究用深度强化学习来为智能体预测游戏动作的方法,论文已被AAAI,2020接收,此技术支...。
更新时间:2024-12-09 18:07:36

雷锋网AI科技评论按,近期Facebook泄露海量用户数据,而且这些数据还被利用来针对性地影响Facebook用户的事情已经闹得沸沸扬扬,除了用户隐私保护这一话题永远都不过时之外,,用来分析用户、影响用户的AI算法应当担负怎么样的责任,这一话题也在AI圈中引起了讨论,Keras作者、谷歌大脑研究员FrançoisChollet也在Tw...。
更新时间:2024-12-09 17:58:36

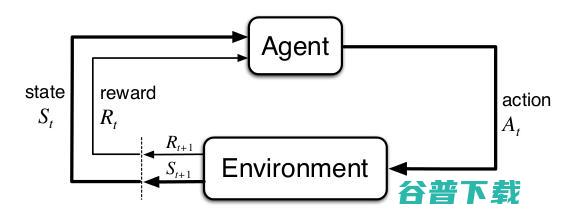
原始的深度强化学习是纯强化学习,其典型问题为马尔科夫决策过程,MDP,马尔科夫决策过程包含一组状态S和动作A,状态的转换是通过概率P,奖励R和一个折衷参数gamma决定的,概率转换P反映了转换和状态转变的奖励之间的关系,状态和奖励仅依赖上一时间步的状态和动作,强化学习为Agent定义了环境,来实现某些动作以最大化奖励,这些动作根据p...。
更新时间:2024-12-09 16:50:37
本系列文章通过通俗易懂的方式介绍强化学习的基本概念,虽然语言通俗,但是内容依旧非常严谨性,文中用很多的公式,对数学公式头疼的读者可能会被吓住,但是如果读者一步一步follow下来,就会发现公式的推导非常自然,对于透彻的理解这些基本概念非常有帮助,除了理论之外,文章还会介绍每种算法的实现代码,深入解答每一行关键代码,让读者不但理解理论和...。
更新时间:2024-12-09 15:38:39
雷锋网消息,8月7日,国际数据挖掘顶会KDD2019上三大竞赛KDDCUP比赛结果出炉,中国参赛者获奖,KDDCUP今年有2800多支注册队伍参赛,包括了230个学术和研究机构,分为三个赛道,常规机器学习竞赛、自动机器学习竞赛、强化学习竞赛,其中,常规机器学习竞赛由百度赞助,包括两个任务,最适合的交通方式推荐、开放研究/应用挑战,在最...。
更新时间:2024-12-09 15:27:57

强化学习在人工智能领域的,扬名立万,,始于2016年DeepMind开发的AlphaGo在围棋竞赛中战胜人类世界冠军李世石,之后,强化学习被广泛应用于人工智能、机器人与自然科学等领域,并取得一系列突破性成果,如DeepMind的Alpha系列,,引起了大批学者的研究兴趣与广泛关注,事实上,强化学习的研究由来已久,远远早于2016年,自...。
更新时间:2024-12-09 15:11:35

清华大学计算机系对话式人工智能课题组多篇论文被ACL2018和IJCAI,ECAI2018会议录用,涉及对话系统、语言生成、强化学习等领域,下面是论文列表及介绍,•GeneratingInformativeResponseswithControlledSentenceFunction作者,柯沛、关健、黄民烈、朱小燕会议,ACL2018...。
更新时间:2024-12-09 15:10:49

 网站首页
网站首页 提交收录
提交收录 收录查询
收录查询 文章资讯
文章资讯 热门排行
热门排行 软文发布
软文发布 自助广告
自助广告